diff --git a/README.md b/README.md
index a285285..818d0aa 100644
--- a/README.md
+++ b/README.md
@@ -1,5 +1,11 @@
# 🦌 DeerFlow - 2.0
+English | [中文](./README_zh.md)
+
+[](./backend/pyproject.toml)
+[](./Makefile)
+[](./LICENSE)
+
 > On February 28th, 2026, DeerFlow claimed the 🏆 #1 spot on GitHub Trending following the launch of version 2. Thanks a million to our incredible community — you made this happen! 💪🔥
@@ -21,8 +27,8 @@ Learn more and see **real demos** on our official website.
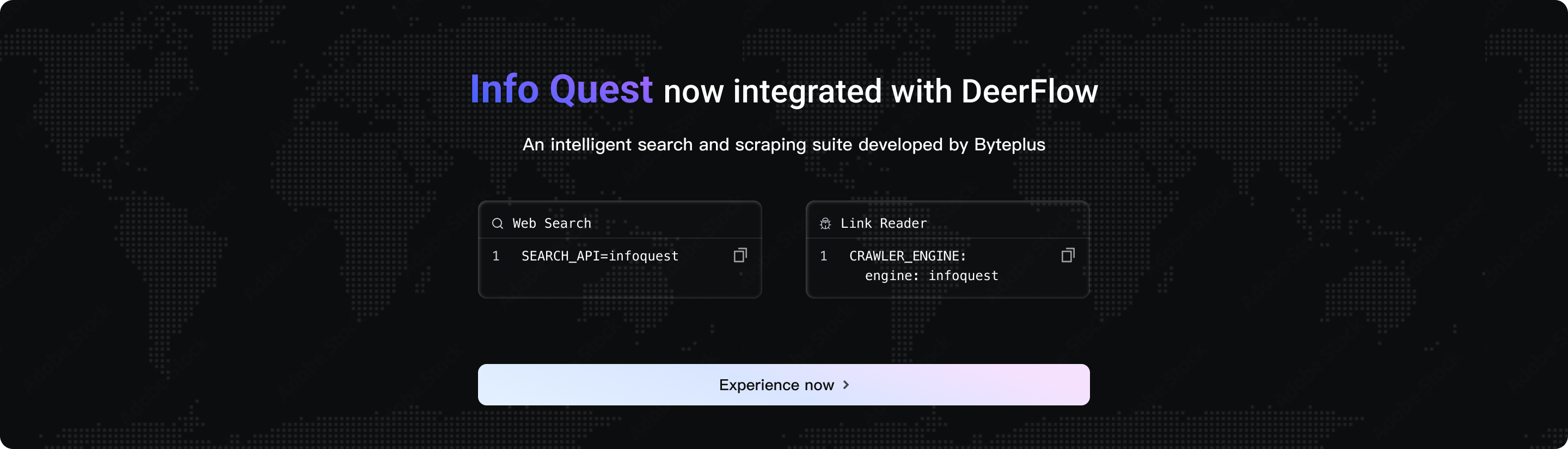
DeerFlow has newly integrated the intelligent search and crawling toolset independently developed by BytePlus--[InfoQuest (supports free online experience)](https://docs.byteplus.com/en/docs/InfoQuest/What_is_Info_Quest)
-
> On February 28th, 2026, DeerFlow claimed the 🏆 #1 spot on GitHub Trending following the launch of version 2. Thanks a million to our incredible community — you made this happen! 💪🔥
@@ -21,8 +27,8 @@ Learn more and see **real demos** on our official website.
DeerFlow has newly integrated the intelligent search and crawling toolset independently developed by BytePlus--[InfoQuest (supports free online experience)](https://docs.byteplus.com/en/docs/InfoQuest/What_is_Info_Quest)
-  diff --git a/README_zh.md b/README_zh.md
new file mode 100644
index 0000000..7379f05
--- /dev/null
+++ b/README_zh.md
@@ -0,0 +1,491 @@
+# 🦌 DeerFlow - 2.0
+
+[English](./README.md) | 中文
+
+[](./backend/pyproject.toml)
+[](./Makefile)
+[](./LICENSE)
+
+
+> 2026 年 2 月 28 日,DeerFlow 2 发布后登上 GitHub Trending 第 1 名。非常感谢社区的支持,这是大家一起做到的。
+
+DeerFlow(**D**eep **E**xploration and **E**fficient **R**esearch **Flow**)是一个开源的 **super agent harness**。它把 **sub-agents**、**memory** 和 **sandbox** 组织在一起,再配合可扩展的 **skills**,让 agent 可以完成几乎任何事情。
+
+https://github.com/user-attachments/assets/a8bcadc4-e040-4cf2-8fda-dd768b999c18
+
+> [!NOTE]
+> **DeerFlow 2.0 是一次彻底重写。** 它和 v1 没有共用代码。如果你要找的是最初的 Deep Research 框架,可以前往 [`1.x` 分支](https://github.com/bytedance/deer-flow/tree/main-1.x)。那里仍然欢迎贡献;当前的主要开发已经转向 2.0。
+
+## 官网
+
+想了解更多,或者直接看**真实演示**,可以访问官网:
+
+**[deerflow.tech](https://deerflow.tech/)**
+
+## 目录
+
+- [🦌 DeerFlow - 2.0](#-deerflow---20)
+ - [官网](#官网)
+ - [InfoQuest](#infoquest)
+ - [目录](#目录)
+ - [快速开始](#快速开始)
+ - [配置](#配置)
+ - [运行应用](#运行应用)
+ - [方式一:Docker(推荐)](#方式一docker推荐)
+ - [方式二:本地开发](#方式二本地开发)
+ - [进阶配置](#进阶配置)
+ - [Sandbox 模式](#sandbox-模式)
+ - [MCP Server](#mcp-server)
+ - [IM 渠道](#im-渠道)
+ - [从 Deep Research 到 Super Agent Harness](#从-deep-research-到-super-agent-harness)
+ - [核心特性](#核心特性)
+ - [Skills 与 Tools](#skills-与-tools)
+ - [Claude Code 集成](#claude-code-集成)
+ - [Sub-Agents](#sub-agents)
+ - [Sandbox 与文件系统](#sandbox-与文件系统)
+ - [Context Engineering](#context-engineering)
+ - [长期记忆](#长期记忆)
+ - [推荐模型](#推荐模型)
+ - [内嵌 Python Client](#内嵌-python-client)
+ - [文档](#文档)
+ - [参与贡献](#参与贡献)
+ - [许可证](#许可证)
+ - [致谢](#致谢)
+ - [核心贡献者](#核心贡献者)
+ - [Star History](#star-history)
+
+## 快速开始
+
+### 配置
+
+1. **克隆 DeerFlow 仓库**
+
+ ```bash
+ git clone https://github.com/bytedance/deer-flow.git
+ cd deer-flow
+ ```
+
+2. **生成本地配置文件**
+
+ 在项目根目录(`deer-flow/`)执行:
+
+ ```bash
+ make config
+ ```
+
+ 这个命令会基于示例模板生成本地配置文件。
+
+3. **配置你要使用的模型**
+
+ 编辑 `config.yaml`,至少定义一个模型:
+
+ ```yaml
+ models:
+ - name: gpt-4 # 内部标识
+ display_name: GPT-4 # 展示名称
+ use: langchain_openai:ChatOpenAI # LangChain 类路径
+ model: gpt-4 # API 使用的模型标识
+ api_key: $OPENAI_API_KEY # API key(推荐使用环境变量)
+ max_tokens: 4096 # 单次请求最大 tokens
+ temperature: 0.7 # 采样温度
+
+ - name: openrouter-gemini-2.5-flash
+ display_name: Gemini 2.5 Flash (OpenRouter)
+ use: langchain_openai:ChatOpenAI
+ model: google/gemini-2.5-flash-preview
+ api_key: $OPENAI_API_KEY # 这里 OpenRouter 依然沿用 OpenAI 兼容字段名
+ base_url: https://openrouter.ai/api/v1
+ ```
+
+ OpenRouter 以及类似的 OpenAI 兼容网关,建议通过 `langchain_openai:ChatOpenAI` 配合 `base_url` 来配置。如果你更想用 provider 自己的环境变量名,也可以直接把 `api_key` 指向对应变量,例如 `api_key: $OPENROUTER_API_KEY`。
+
+4. **为已配置的模型设置 API key**
+
+ 可任选以下一种方式:
+
+- 方式 A:编辑项目根目录下的 `.env` 文件(推荐)
+
+ ```bash
+ TAVILY_API_KEY=your-tavily-api-key
+ OPENAI_API_KEY=your-openai-api-key
+ # 如果配置使用的是 langchain_openai:ChatOpenAI + base_url,OpenRouter 也会读取 OPENAI_API_KEY
+ # 其他 provider 的 key 按需补充
+ INFOQUEST_API_KEY=your-infoquest-api-key
+ ```
+
+- 方式 B:在 shell 中导出环境变量
+
+ ```bash
+ export OPENAI_API_KEY=your-openai-api-key
+ ```
+
+- 方式 C:直接编辑 `config.yaml`(不建议用于生产环境)
+
+ ```yaml
+ models:
+ - name: gpt-4
+ api_key: your-actual-api-key-here # 替换为真实 key
+ ```
+
+### 运行应用
+
+#### 方式一:Docker(推荐)
+
+**开发模式**(支持热更新,挂载源码):
+
+```bash
+make docker-init # 拉取 sandbox 镜像(首次运行或镜像更新时执行)
+make docker-start # 启动服务(会根据 config.yaml 自动判断 sandbox 模式)
+```
+
+如果 `config.yaml` 使用的是 provisioner 模式(`sandbox.use: deerflow.community.aio_sandbox:AioSandboxProvider` 且配置了 `provisioner_url`),`make docker-start` 才会启动 `provisioner`。
+
+**生产模式**(本地构建镜像,并挂载运行期配置与数据):
+
+```bash
+make up # 构建镜像并启动全部生产服务
+make down # 停止并移除容器
+```
+
+> [!NOTE]
+> 当前 LangGraph agent server 通过开源 CLI 服务 `langgraph dev` 运行。
+
+访问地址:http://localhost:2026
+
+更完整的 Docker 开发说明见 [CONTRIBUTING.md](CONTRIBUTING.md)。
+
+#### 方式二:本地开发
+
+如果你更希望直接在本地启动各个服务:
+
+前提:先完成上面的“配置”步骤(`make config` 和模型 API key 配置)。`make dev` 需要有效配置文件,默认读取项目根目录下的 `config.yaml`,也可以通过 `DEER_FLOW_CONFIG_PATH` 覆盖。
+
+1. **检查依赖环境**:
+ ```bash
+ make check # 校验 Node.js 22+、pnpm、uv、nginx
+ ```
+
+2. **安装依赖**:
+ ```bash
+ make install # 安装 backend + frontend 依赖
+ ```
+
+3. **(可选)预拉取 sandbox 镜像**:
+ ```bash
+ # 如果使用 Docker / Container sandbox,建议先执行
+ make setup-sandbox
+ ```
+
+4. **启动服务**:
+ ```bash
+ make dev
+ ```
+
+5. **访问地址**:http://localhost:2026
+
+### 进阶配置
+#### Sandbox 模式
+
+DeerFlow 支持多种 sandbox 执行方式:
+- **本地执行**(直接在宿主机上运行 sandbox 代码)
+- **Docker 执行**(在隔离的 Docker 容器里运行 sandbox 代码)
+- **Docker + Kubernetes 执行**(通过 provisioner 服务在 Kubernetes Pod 中运行 sandbox 代码)
+
+Docker 开发时,服务启动行为会遵循 `config.yaml` 里的 sandbox 模式。在 Local / Docker 模式下,不会启动 `provisioner`。
+
+如果要配置你自己的模式,参见 [Sandbox 配置指南](backend/docs/CONFIGURATION.md#sandbox)。
+
+#### MCP Server
+
+DeerFlow 支持可配置的 MCP Server 和 skills,用来扩展能力。
+对于 HTTP/SSE MCP Server,还支持 OAuth token 流程(`client_credentials`、`refresh_token`)。
+详细说明见 [MCP Server 指南](backend/docs/MCP_SERVER.md)。
+
+#### IM 渠道
+
+DeerFlow 支持从即时通讯应用接收任务。只要配置完成,对应渠道会自动启动,而且都不需要公网 IP。
+
+| 渠道 | 传输方式 | 上手难度 |
+|---------|-----------|------------|
+| Telegram | Bot API(long-polling) | 简单 |
+| Slack | Socket Mode | 中等 |
+| Feishu / Lark | WebSocket | 中等 |
+
+**`config.yaml` 中的配置示例:**
+
+```yaml
+channels:
+ # LangGraph Server URL(默认:http://localhost:2024)
+ langgraph_url: http://localhost:2024
+ # Gateway API URL(默认:http://localhost:8001)
+ gateway_url: http://localhost:8001
+
+ # 可选:所有移动端渠道共用的全局 session 默认值
+ session:
+ assistant_id: lead_agent
+ config:
+ recursion_limit: 100
+ context:
+ thinking_enabled: true
+ is_plan_mode: false
+ subagent_enabled: false
+
+ feishu:
+ enabled: true
+ app_id: $FEISHU_APP_ID
+ app_secret: $FEISHU_APP_SECRET
+
+ slack:
+ enabled: true
+ bot_token: $SLACK_BOT_TOKEN # xoxb-...
+ app_token: $SLACK_APP_TOKEN # xapp-...(Socket Mode)
+ allowed_users: [] # 留空表示允许所有人
+
+ telegram:
+ enabled: true
+ bot_token: $TELEGRAM_BOT_TOKEN
+ allowed_users: [] # 留空表示允许所有人
+
+ # 可选:按渠道 / 按用户单独覆盖 session 配置
+ session:
+ assistant_id: mobile_agent
+ context:
+ thinking_enabled: false
+ users:
+ "123456789":
+ assistant_id: vip_agent
+ config:
+ recursion_limit: 150
+ context:
+ thinking_enabled: true
+ subagent_enabled: true
+```
+
+在 `.env` 里设置对应的 API key:
+
+```bash
+# Telegram
+TELEGRAM_BOT_TOKEN=123456789:ABCdefGHIjklMNOpqrSTUvwxYZ
+
+# Slack
+SLACK_BOT_TOKEN=xoxb-...
+SLACK_APP_TOKEN=xapp-...
+
+# Feishu / Lark
+FEISHU_APP_ID=cli_xxxx
+FEISHU_APP_SECRET=your_app_secret
+```
+
+**Telegram 配置**
+
+1. 打开 [@BotFather](https://t.me/BotFather),发送 `/newbot`,复制生成的 HTTP API token。
+2. 在 `.env` 中设置 `TELEGRAM_BOT_TOKEN`,并在 `config.yaml` 里启用该渠道。
+
+**Slack 配置**
+
+1. 前往 [api.slack.com/apps](https://api.slack.com/apps) 创建 Slack App:Create New App → From scratch。
+2. 在 **OAuth & Permissions** 中添加 Bot Token Scopes:`app_mentions:read`、`chat:write`、`im:history`、`im:read`、`im:write`、`files:write`。
+3. 启用 **Socket Mode**,生成带 `connections:write` 权限的 App-Level Token(`xapp-...`)。
+4. 在 **Event Subscriptions** 中订阅 bot events:`app_mention`、`message.im`。
+5. 在 `.env` 中设置 `SLACK_BOT_TOKEN` 和 `SLACK_APP_TOKEN`,并在 `config.yaml` 中启用该渠道。
+
+**Feishu / Lark 配置**
+
+1. 在 [飞书开放平台](https://open.feishu.cn/) 创建应用,并启用 **Bot** 能力。
+2. 添加权限:`im:message`、`im:message.p2p_msg:readonly`、`im:resource`。
+3. 在 **事件订阅** 中订阅 `im.message.receive_v1`,连接方式选择 **长连接**。
+4. 复制 App ID 和 App Secret,在 `.env` 中设置 `FEISHU_APP_ID` 和 `FEISHU_APP_SECRET`,并在 `config.yaml` 中启用该渠道。
+
+**命令**
+
+渠道连接完成后,你可以直接在聊天窗口里和 DeerFlow 交互:
+
+| 命令 | 说明 |
+|---------|-------------|
+| `/new` | 开启新对话 |
+| `/status` | 查看当前 thread 信息 |
+| `/models` | 列出可用模型 |
+| `/memory` | 查看 memory |
+| `/help` | 查看帮助 |
+
+> 没有命令前缀的消息会被当作普通聊天处理。DeerFlow 会自动创建 thread,并以对话方式回复。
+
+## 从 Deep Research 到 Super Agent Harness
+
+DeerFlow 最初是一个 Deep Research 框架,后来社区把它一路推到了更远的地方。上线之后,开发者拿它去做的事情早就不止研究:搭数据流水线、生成演示文稿、快速起 dashboard、自动化内容流程,很多方向一开始连我们自己都没想到。
+
+这让我们意识到一件事:DeerFlow 不只是一个研究工具。它更像一个 **harness**,一个真正让 agents 把事情做完的运行时基础设施。
+
+所以我们把它从头重做了一遍。
+
+DeerFlow 2.0 不再是一个需要你自己拼装的 framework。它是一个开箱即用、同时又足够可扩展的 super agent harness。基于 LangGraph 和 LangChain 构建,默认就带上了 agent 真正会用到的关键能力:文件系统、memory、skills、sandbox 执行环境,以及为复杂多步骤任务做规划、拉起 sub-agents 的能力。
+
+你可以直接拿来用,也可以拆开重组,改成你自己的样子。
+
+## 核心特性
+
+### Skills 与 Tools
+
+Skills 是 DeerFlow 能做“几乎任何事”的关键。
+
+标准的 Agent Skill 是一种结构化能力模块,通常就是一个 Markdown 文件,里面定义了工作流、最佳实践,以及相关的参考资源。DeerFlow 自带一批内置 skills,覆盖研究、报告生成、演示文稿制作、网页生成、图像和视频生成等场景。真正有意思的地方在于它的扩展性:你可以加自己的 skills,替换内置 skills,或者把多个 skills 组合成复合工作流。
+
+Skills 采用按需渐进加载,不会一次性把所有内容都塞进上下文。只有任务确实需要时才加载,这样能把上下文窗口控制得更干净,也更适合对 token 比较敏感的模型。
+
+通过 Gateway 安装 `.skill` 压缩包时,DeerFlow 会接受标准的可选 frontmatter 元数据,比如 `version`、`author`、`compatibility`,不会把本来合法的外部 skill 拒之门外。
+
+Tools 也是同样的思路。DeerFlow 自带一组核心工具:网页搜索、网页抓取、文件操作、bash 执行;同时也支持通过 MCP Server 和 Python 函数扩展自定义工具。你可以替换任何一项,也可以继续往里加。
+
+Gateway 生成后续建议时,现在会先把普通字符串输出和 block/list 风格的富文本内容统一归一化,再去解析 JSON 数组响应,因此不同 provider 的内容包装方式不会再悄悄把建议吞掉。
+
+```text
+# sandbox 容器内的路径
+/mnt/skills/public
+├── research/SKILL.md
+├── report-generation/SKILL.md
+├── slide-creation/SKILL.md
+├── web-page/SKILL.md
+└── image-generation/SKILL.md
+
+/mnt/skills/custom
+└── your-custom-skill/SKILL.md ← 你的 skill
+```
+
+#### Claude Code 集成
+
+借助 `claude-to-deerflow` skill,你可以直接在 [Claude Code](https://docs.anthropic.com/en/docs/claude-code) 里和正在运行的 DeerFlow 实例交互。不用离开终端,就能下发研究任务、查看状态、管理 threads。
+
+**安装这个 skill:**
+
+```bash
+npx skills add https://github.com/bytedance/deer-flow --skill claude-to-deerflow
+```
+
+然后确认 DeerFlow 已经启动(默认地址是 `http://localhost:2026`),在 Claude Code 里使用 `/claude-to-deerflow` 命令即可。
+
+**你可以做的事情包括:**
+- 给 DeerFlow 发送消息,并接收流式响应
+- 选择执行模式:flash(更快)、standard、pro(规划模式)、ultra(sub-agents 模式)
+- 检查 DeerFlow 健康状态,列出 models / skills / agents
+- 管理 threads 和会话历史
+- 上传文件做分析
+
+**环境变量**(可选,用于自定义端点):
+
+```bash
+DEERFLOW_URL=http://localhost:2026 # 统一代理基地址
+DEERFLOW_GATEWAY_URL=http://localhost:2026 # Gateway API
+DEERFLOW_LANGGRAPH_URL=http://localhost:2026/api/langgraph # LangGraph API
+```
+
+完整 API 说明见 [`skills/public/claude-to-deerflow/SKILL.md`](skills/public/claude-to-deerflow/SKILL.md)。
+
+### Sub-Agents
+
+复杂任务通常不可能一次完成,DeerFlow 会先拆解,再执行。
+
+lead agent 可以按需动态拉起 sub-agents。每个 sub-agent 都有自己独立的上下文、工具和终止条件。只要条件允许,它们就会并行运行,返回结构化结果,最后再由 lead agent 汇总成一份完整输出。
+
+这也是 DeerFlow 能处理从几分钟到几小时任务的原因。比如一个研究任务,可以拆成十几个 sub-agents,分别探索不同方向,最后合并成一份报告,或者一个网站,或者一套带生成视觉内容的演示文稿。一个 harness,多路并行。
+
+### Sandbox 与文件系统
+
+DeerFlow 不只是“会说它能做”,它是真的有一台自己的“电脑”。
+
+每个任务都运行在隔离的 Docker 容器里,里面有完整的文件系统,包括 skills、workspace、uploads、outputs。agent 可以读写和编辑文件,可以执行 bash 命令和代码,也可以查看图片。整个过程都在 sandbox 内完成,可审计、会隔离,不会在不同 session 之间互相污染。
+
+这就是“带工具的聊天机器人”和“真正有执行环境的 agent”之间的差别。
+
+```text
+# sandbox 容器内的路径
+/mnt/user-data/
+├── uploads/ ← 你的文件
+├── workspace/ ← agents 的工作目录
+└── outputs/ ← 最终交付物
+```
+
+### Context Engineering
+
+**隔离的 Sub-Agent Context**:每个 sub-agent 都在自己独立的上下文里运行。它看不到主 agent 的上下文,也看不到其他 sub-agents 的上下文。这样做的目的很直接,就是让它只聚焦当前任务,不被无关信息干扰。
+
+**摘要压缩**:在单个 session 内,DeerFlow 会比较积极地管理上下文,包括总结已完成的子任务、把中间结果转存到文件系统、压缩暂时不重要的信息。这样在长链路、多步骤任务里,它也能保持聚焦,而不会轻易把上下文窗口打爆。
+
+### 长期记忆
+
+大多数 agents 会在对话结束后把一切都忘掉,DeerFlow 不一样。
+
+跨 session 使用时,DeerFlow 会逐步积累关于你的持久 memory,包括你的个人偏好、知识背景,以及长期沉淀下来的工作习惯。你用得越多,它越了解你的写作风格、技术栈和重复出现的工作流。memory 保存在本地,控制权也始终在你手里。
+
+## 推荐模型
+
+DeerFlow 对模型没有强绑定,只要实现了 OpenAI 兼容 API 的 LLM,理论上都可以接入。不过在下面这些能力上表现更强的模型,通常会更适合 DeerFlow:
+
+- **长上下文窗口**(100k+ tokens),适合深度研究和多步骤任务
+- **推理能力**,适合自适应规划和复杂拆解
+- **多模态输入**,适合理解图片和视频
+- **稳定的 tool use 能力**,适合可靠的函数调用和结构化输出
+
+## 内嵌 Python Client
+
+DeerFlow 也可以作为内嵌的 Python 库使用,不必启动完整的 HTTP 服务。`DeerFlowClient` 提供了进程内的直接访问方式,覆盖所有 agent 和 Gateway 能力,返回的数据结构与 HTTP Gateway API 保持一致:
+
+```python
+from deerflow.client import DeerFlowClient
+
+client = DeerFlowClient()
+
+# Chat
+response = client.chat("Analyze this paper for me", thread_id="my-thread")
+
+# Streaming(LangGraph SSE 协议:values、messages-tuple、end)
+for event in client.stream("hello"):
+ if event.type == "messages-tuple" and event.data.get("type") == "ai":
+ print(event.data["content"])
+
+# 配置与管理:返回值与 Gateway 对齐的 dict
+models = client.list_models() # {"models": [...]}
+skills = client.list_skills() # {"skills": [...]}
+client.update_skill("web-search", enabled=True)
+client.upload_files("thread-1", ["./report.pdf"]) # {"success": True, "files": [...]}
+```
+
+所有返回 dict 的方法都会在 CI 中通过 Gateway 的 Pydantic 响应模型校验(`TestGatewayConformance`),以确保内嵌 client 始终和 HTTP API schema 保持同步。完整 API 说明见 `backend/packages/harness/deerflow/client.py`。
+
+## 文档
+
+- [贡献指南](CONTRIBUTING.md) - 开发环境搭建与协作流程
+- [配置指南](backend/docs/CONFIGURATION.md) - 安装与配置说明
+- [架构概览](backend/CLAUDE.md) - 技术架构说明
+- [后端架构](backend/README.md) - 后端架构与 API 参考
+
+## 参与贡献
+
+欢迎参与贡献。开发环境、工作流和相关规范见 [CONTRIBUTING.md](CONTRIBUTING.md)。
+
+目前回归测试已经覆盖 Docker sandbox 模式识别,以及 `backend/tests/` 中 provisioner kubeconfig-path 处理相关测试。
+
+## 许可证
+
+本项目采用 [MIT License](./LICENSE) 开源发布。
+
+## 致谢
+
+DeerFlow 建立在开源社区大量优秀工作的基础上。所有让 DeerFlow 成为可能的项目和贡献者,我们都心怀感谢。毫不夸张地说,我们是站在巨人的肩膀上继续往前走。
+
+特别感谢以下项目带来的关键支持:
+
+- **[LangChain](https://github.com/langchain-ai/langchain)**:它们提供的优秀框架支撑了我们的 LLM 交互与 chains,让整体集成和能力编排顺畅可用。
+- **[LangGraph](https://github.com/langchain-ai/langgraph)**:它们在多 agent 编排上的创新方式,是 DeerFlow 复杂工作流得以成立的重要基础。
+
+这些项目体现了开源协作真正的力量,我们也很高兴能继续建立在这些基础之上。
+
+### 核心贡献者
+
+感谢 `DeerFlow` 的核心作者,是他们的判断、投入和持续推进,才让这个项目真正落地:
+
+- **[Daniel Walnut](https://github.com/hetaoBackend/)**
+- **[Henry Li](https://github.com/magiccube/)**
+
+## Star History
+
+[](https://star-history.com/#bytedance/deer-flow&Date)
diff --git a/README_zh.md b/README_zh.md
new file mode 100644
index 0000000..7379f05
--- /dev/null
+++ b/README_zh.md
@@ -0,0 +1,491 @@
+# 🦌 DeerFlow - 2.0
+
+[English](./README.md) | 中文
+
+[](./backend/pyproject.toml)
+[](./Makefile)
+[](./LICENSE)
+
+
+> 2026 年 2 月 28 日,DeerFlow 2 发布后登上 GitHub Trending 第 1 名。非常感谢社区的支持,这是大家一起做到的。
+
+DeerFlow(**D**eep **E**xploration and **E**fficient **R**esearch **Flow**)是一个开源的 **super agent harness**。它把 **sub-agents**、**memory** 和 **sandbox** 组织在一起,再配合可扩展的 **skills**,让 agent 可以完成几乎任何事情。
+
+https://github.com/user-attachments/assets/a8bcadc4-e040-4cf2-8fda-dd768b999c18
+
+> [!NOTE]
+> **DeerFlow 2.0 是一次彻底重写。** 它和 v1 没有共用代码。如果你要找的是最初的 Deep Research 框架,可以前往 [`1.x` 分支](https://github.com/bytedance/deer-flow/tree/main-1.x)。那里仍然欢迎贡献;当前的主要开发已经转向 2.0。
+
+## 官网
+
+想了解更多,或者直接看**真实演示**,可以访问官网:
+
+**[deerflow.tech](https://deerflow.tech/)**
+
+## 目录
+
+- [🦌 DeerFlow - 2.0](#-deerflow---20)
+ - [官网](#官网)
+ - [InfoQuest](#infoquest)
+ - [目录](#目录)
+ - [快速开始](#快速开始)
+ - [配置](#配置)
+ - [运行应用](#运行应用)
+ - [方式一:Docker(推荐)](#方式一docker推荐)
+ - [方式二:本地开发](#方式二本地开发)
+ - [进阶配置](#进阶配置)
+ - [Sandbox 模式](#sandbox-模式)
+ - [MCP Server](#mcp-server)
+ - [IM 渠道](#im-渠道)
+ - [从 Deep Research 到 Super Agent Harness](#从-deep-research-到-super-agent-harness)
+ - [核心特性](#核心特性)
+ - [Skills 与 Tools](#skills-与-tools)
+ - [Claude Code 集成](#claude-code-集成)
+ - [Sub-Agents](#sub-agents)
+ - [Sandbox 与文件系统](#sandbox-与文件系统)
+ - [Context Engineering](#context-engineering)
+ - [长期记忆](#长期记忆)
+ - [推荐模型](#推荐模型)
+ - [内嵌 Python Client](#内嵌-python-client)
+ - [文档](#文档)
+ - [参与贡献](#参与贡献)
+ - [许可证](#许可证)
+ - [致谢](#致谢)
+ - [核心贡献者](#核心贡献者)
+ - [Star History](#star-history)
+
+## 快速开始
+
+### 配置
+
+1. **克隆 DeerFlow 仓库**
+
+ ```bash
+ git clone https://github.com/bytedance/deer-flow.git
+ cd deer-flow
+ ```
+
+2. **生成本地配置文件**
+
+ 在项目根目录(`deer-flow/`)执行:
+
+ ```bash
+ make config
+ ```
+
+ 这个命令会基于示例模板生成本地配置文件。
+
+3. **配置你要使用的模型**
+
+ 编辑 `config.yaml`,至少定义一个模型:
+
+ ```yaml
+ models:
+ - name: gpt-4 # 内部标识
+ display_name: GPT-4 # 展示名称
+ use: langchain_openai:ChatOpenAI # LangChain 类路径
+ model: gpt-4 # API 使用的模型标识
+ api_key: $OPENAI_API_KEY # API key(推荐使用环境变量)
+ max_tokens: 4096 # 单次请求最大 tokens
+ temperature: 0.7 # 采样温度
+
+ - name: openrouter-gemini-2.5-flash
+ display_name: Gemini 2.5 Flash (OpenRouter)
+ use: langchain_openai:ChatOpenAI
+ model: google/gemini-2.5-flash-preview
+ api_key: $OPENAI_API_KEY # 这里 OpenRouter 依然沿用 OpenAI 兼容字段名
+ base_url: https://openrouter.ai/api/v1
+ ```
+
+ OpenRouter 以及类似的 OpenAI 兼容网关,建议通过 `langchain_openai:ChatOpenAI` 配合 `base_url` 来配置。如果你更想用 provider 自己的环境变量名,也可以直接把 `api_key` 指向对应变量,例如 `api_key: $OPENROUTER_API_KEY`。
+
+4. **为已配置的模型设置 API key**
+
+ 可任选以下一种方式:
+
+- 方式 A:编辑项目根目录下的 `.env` 文件(推荐)
+
+ ```bash
+ TAVILY_API_KEY=your-tavily-api-key
+ OPENAI_API_KEY=your-openai-api-key
+ # 如果配置使用的是 langchain_openai:ChatOpenAI + base_url,OpenRouter 也会读取 OPENAI_API_KEY
+ # 其他 provider 的 key 按需补充
+ INFOQUEST_API_KEY=your-infoquest-api-key
+ ```
+
+- 方式 B:在 shell 中导出环境变量
+
+ ```bash
+ export OPENAI_API_KEY=your-openai-api-key
+ ```
+
+- 方式 C:直接编辑 `config.yaml`(不建议用于生产环境)
+
+ ```yaml
+ models:
+ - name: gpt-4
+ api_key: your-actual-api-key-here # 替换为真实 key
+ ```
+
+### 运行应用
+
+#### 方式一:Docker(推荐)
+
+**开发模式**(支持热更新,挂载源码):
+
+```bash
+make docker-init # 拉取 sandbox 镜像(首次运行或镜像更新时执行)
+make docker-start # 启动服务(会根据 config.yaml 自动判断 sandbox 模式)
+```
+
+如果 `config.yaml` 使用的是 provisioner 模式(`sandbox.use: deerflow.community.aio_sandbox:AioSandboxProvider` 且配置了 `provisioner_url`),`make docker-start` 才会启动 `provisioner`。
+
+**生产模式**(本地构建镜像,并挂载运行期配置与数据):
+
+```bash
+make up # 构建镜像并启动全部生产服务
+make down # 停止并移除容器
+```
+
+> [!NOTE]
+> 当前 LangGraph agent server 通过开源 CLI 服务 `langgraph dev` 运行。
+
+访问地址:http://localhost:2026
+
+更完整的 Docker 开发说明见 [CONTRIBUTING.md](CONTRIBUTING.md)。
+
+#### 方式二:本地开发
+
+如果你更希望直接在本地启动各个服务:
+
+前提:先完成上面的“配置”步骤(`make config` 和模型 API key 配置)。`make dev` 需要有效配置文件,默认读取项目根目录下的 `config.yaml`,也可以通过 `DEER_FLOW_CONFIG_PATH` 覆盖。
+
+1. **检查依赖环境**:
+ ```bash
+ make check # 校验 Node.js 22+、pnpm、uv、nginx
+ ```
+
+2. **安装依赖**:
+ ```bash
+ make install # 安装 backend + frontend 依赖
+ ```
+
+3. **(可选)预拉取 sandbox 镜像**:
+ ```bash
+ # 如果使用 Docker / Container sandbox,建议先执行
+ make setup-sandbox
+ ```
+
+4. **启动服务**:
+ ```bash
+ make dev
+ ```
+
+5. **访问地址**:http://localhost:2026
+
+### 进阶配置
+#### Sandbox 模式
+
+DeerFlow 支持多种 sandbox 执行方式:
+- **本地执行**(直接在宿主机上运行 sandbox 代码)
+- **Docker 执行**(在隔离的 Docker 容器里运行 sandbox 代码)
+- **Docker + Kubernetes 执行**(通过 provisioner 服务在 Kubernetes Pod 中运行 sandbox 代码)
+
+Docker 开发时,服务启动行为会遵循 `config.yaml` 里的 sandbox 模式。在 Local / Docker 模式下,不会启动 `provisioner`。
+
+如果要配置你自己的模式,参见 [Sandbox 配置指南](backend/docs/CONFIGURATION.md#sandbox)。
+
+#### MCP Server
+
+DeerFlow 支持可配置的 MCP Server 和 skills,用来扩展能力。
+对于 HTTP/SSE MCP Server,还支持 OAuth token 流程(`client_credentials`、`refresh_token`)。
+详细说明见 [MCP Server 指南](backend/docs/MCP_SERVER.md)。
+
+#### IM 渠道
+
+DeerFlow 支持从即时通讯应用接收任务。只要配置完成,对应渠道会自动启动,而且都不需要公网 IP。
+
+| 渠道 | 传输方式 | 上手难度 |
+|---------|-----------|------------|
+| Telegram | Bot API(long-polling) | 简单 |
+| Slack | Socket Mode | 中等 |
+| Feishu / Lark | WebSocket | 中等 |
+
+**`config.yaml` 中的配置示例:**
+
+```yaml
+channels:
+ # LangGraph Server URL(默认:http://localhost:2024)
+ langgraph_url: http://localhost:2024
+ # Gateway API URL(默认:http://localhost:8001)
+ gateway_url: http://localhost:8001
+
+ # 可选:所有移动端渠道共用的全局 session 默认值
+ session:
+ assistant_id: lead_agent
+ config:
+ recursion_limit: 100
+ context:
+ thinking_enabled: true
+ is_plan_mode: false
+ subagent_enabled: false
+
+ feishu:
+ enabled: true
+ app_id: $FEISHU_APP_ID
+ app_secret: $FEISHU_APP_SECRET
+
+ slack:
+ enabled: true
+ bot_token: $SLACK_BOT_TOKEN # xoxb-...
+ app_token: $SLACK_APP_TOKEN # xapp-...(Socket Mode)
+ allowed_users: [] # 留空表示允许所有人
+
+ telegram:
+ enabled: true
+ bot_token: $TELEGRAM_BOT_TOKEN
+ allowed_users: [] # 留空表示允许所有人
+
+ # 可选:按渠道 / 按用户单独覆盖 session 配置
+ session:
+ assistant_id: mobile_agent
+ context:
+ thinking_enabled: false
+ users:
+ "123456789":
+ assistant_id: vip_agent
+ config:
+ recursion_limit: 150
+ context:
+ thinking_enabled: true
+ subagent_enabled: true
+```
+
+在 `.env` 里设置对应的 API key:
+
+```bash
+# Telegram
+TELEGRAM_BOT_TOKEN=123456789:ABCdefGHIjklMNOpqrSTUvwxYZ
+
+# Slack
+SLACK_BOT_TOKEN=xoxb-...
+SLACK_APP_TOKEN=xapp-...
+
+# Feishu / Lark
+FEISHU_APP_ID=cli_xxxx
+FEISHU_APP_SECRET=your_app_secret
+```
+
+**Telegram 配置**
+
+1. 打开 [@BotFather](https://t.me/BotFather),发送 `/newbot`,复制生成的 HTTP API token。
+2. 在 `.env` 中设置 `TELEGRAM_BOT_TOKEN`,并在 `config.yaml` 里启用该渠道。
+
+**Slack 配置**
+
+1. 前往 [api.slack.com/apps](https://api.slack.com/apps) 创建 Slack App:Create New App → From scratch。
+2. 在 **OAuth & Permissions** 中添加 Bot Token Scopes:`app_mentions:read`、`chat:write`、`im:history`、`im:read`、`im:write`、`files:write`。
+3. 启用 **Socket Mode**,生成带 `connections:write` 权限的 App-Level Token(`xapp-...`)。
+4. 在 **Event Subscriptions** 中订阅 bot events:`app_mention`、`message.im`。
+5. 在 `.env` 中设置 `SLACK_BOT_TOKEN` 和 `SLACK_APP_TOKEN`,并在 `config.yaml` 中启用该渠道。
+
+**Feishu / Lark 配置**
+
+1. 在 [飞书开放平台](https://open.feishu.cn/) 创建应用,并启用 **Bot** 能力。
+2. 添加权限:`im:message`、`im:message.p2p_msg:readonly`、`im:resource`。
+3. 在 **事件订阅** 中订阅 `im.message.receive_v1`,连接方式选择 **长连接**。
+4. 复制 App ID 和 App Secret,在 `.env` 中设置 `FEISHU_APP_ID` 和 `FEISHU_APP_SECRET`,并在 `config.yaml` 中启用该渠道。
+
+**命令**
+
+渠道连接完成后,你可以直接在聊天窗口里和 DeerFlow 交互:
+
+| 命令 | 说明 |
+|---------|-------------|
+| `/new` | 开启新对话 |
+| `/status` | 查看当前 thread 信息 |
+| `/models` | 列出可用模型 |
+| `/memory` | 查看 memory |
+| `/help` | 查看帮助 |
+
+> 没有命令前缀的消息会被当作普通聊天处理。DeerFlow 会自动创建 thread,并以对话方式回复。
+
+## 从 Deep Research 到 Super Agent Harness
+
+DeerFlow 最初是一个 Deep Research 框架,后来社区把它一路推到了更远的地方。上线之后,开发者拿它去做的事情早就不止研究:搭数据流水线、生成演示文稿、快速起 dashboard、自动化内容流程,很多方向一开始连我们自己都没想到。
+
+这让我们意识到一件事:DeerFlow 不只是一个研究工具。它更像一个 **harness**,一个真正让 agents 把事情做完的运行时基础设施。
+
+所以我们把它从头重做了一遍。
+
+DeerFlow 2.0 不再是一个需要你自己拼装的 framework。它是一个开箱即用、同时又足够可扩展的 super agent harness。基于 LangGraph 和 LangChain 构建,默认就带上了 agent 真正会用到的关键能力:文件系统、memory、skills、sandbox 执行环境,以及为复杂多步骤任务做规划、拉起 sub-agents 的能力。
+
+你可以直接拿来用,也可以拆开重组,改成你自己的样子。
+
+## 核心特性
+
+### Skills 与 Tools
+
+Skills 是 DeerFlow 能做“几乎任何事”的关键。
+
+标准的 Agent Skill 是一种结构化能力模块,通常就是一个 Markdown 文件,里面定义了工作流、最佳实践,以及相关的参考资源。DeerFlow 自带一批内置 skills,覆盖研究、报告生成、演示文稿制作、网页生成、图像和视频生成等场景。真正有意思的地方在于它的扩展性:你可以加自己的 skills,替换内置 skills,或者把多个 skills 组合成复合工作流。
+
+Skills 采用按需渐进加载,不会一次性把所有内容都塞进上下文。只有任务确实需要时才加载,这样能把上下文窗口控制得更干净,也更适合对 token 比较敏感的模型。
+
+通过 Gateway 安装 `.skill` 压缩包时,DeerFlow 会接受标准的可选 frontmatter 元数据,比如 `version`、`author`、`compatibility`,不会把本来合法的外部 skill 拒之门外。
+
+Tools 也是同样的思路。DeerFlow 自带一组核心工具:网页搜索、网页抓取、文件操作、bash 执行;同时也支持通过 MCP Server 和 Python 函数扩展自定义工具。你可以替换任何一项,也可以继续往里加。
+
+Gateway 生成后续建议时,现在会先把普通字符串输出和 block/list 风格的富文本内容统一归一化,再去解析 JSON 数组响应,因此不同 provider 的内容包装方式不会再悄悄把建议吞掉。
+
+```text
+# sandbox 容器内的路径
+/mnt/skills/public
+├── research/SKILL.md
+├── report-generation/SKILL.md
+├── slide-creation/SKILL.md
+├── web-page/SKILL.md
+└── image-generation/SKILL.md
+
+/mnt/skills/custom
+└── your-custom-skill/SKILL.md ← 你的 skill
+```
+
+#### Claude Code 集成
+
+借助 `claude-to-deerflow` skill,你可以直接在 [Claude Code](https://docs.anthropic.com/en/docs/claude-code) 里和正在运行的 DeerFlow 实例交互。不用离开终端,就能下发研究任务、查看状态、管理 threads。
+
+**安装这个 skill:**
+
+```bash
+npx skills add https://github.com/bytedance/deer-flow --skill claude-to-deerflow
+```
+
+然后确认 DeerFlow 已经启动(默认地址是 `http://localhost:2026`),在 Claude Code 里使用 `/claude-to-deerflow` 命令即可。
+
+**你可以做的事情包括:**
+- 给 DeerFlow 发送消息,并接收流式响应
+- 选择执行模式:flash(更快)、standard、pro(规划模式)、ultra(sub-agents 模式)
+- 检查 DeerFlow 健康状态,列出 models / skills / agents
+- 管理 threads 和会话历史
+- 上传文件做分析
+
+**环境变量**(可选,用于自定义端点):
+
+```bash
+DEERFLOW_URL=http://localhost:2026 # 统一代理基地址
+DEERFLOW_GATEWAY_URL=http://localhost:2026 # Gateway API
+DEERFLOW_LANGGRAPH_URL=http://localhost:2026/api/langgraph # LangGraph API
+```
+
+完整 API 说明见 [`skills/public/claude-to-deerflow/SKILL.md`](skills/public/claude-to-deerflow/SKILL.md)。
+
+### Sub-Agents
+
+复杂任务通常不可能一次完成,DeerFlow 会先拆解,再执行。
+
+lead agent 可以按需动态拉起 sub-agents。每个 sub-agent 都有自己独立的上下文、工具和终止条件。只要条件允许,它们就会并行运行,返回结构化结果,最后再由 lead agent 汇总成一份完整输出。
+
+这也是 DeerFlow 能处理从几分钟到几小时任务的原因。比如一个研究任务,可以拆成十几个 sub-agents,分别探索不同方向,最后合并成一份报告,或者一个网站,或者一套带生成视觉内容的演示文稿。一个 harness,多路并行。
+
+### Sandbox 与文件系统
+
+DeerFlow 不只是“会说它能做”,它是真的有一台自己的“电脑”。
+
+每个任务都运行在隔离的 Docker 容器里,里面有完整的文件系统,包括 skills、workspace、uploads、outputs。agent 可以读写和编辑文件,可以执行 bash 命令和代码,也可以查看图片。整个过程都在 sandbox 内完成,可审计、会隔离,不会在不同 session 之间互相污染。
+
+这就是“带工具的聊天机器人”和“真正有执行环境的 agent”之间的差别。
+
+```text
+# sandbox 容器内的路径
+/mnt/user-data/
+├── uploads/ ← 你的文件
+├── workspace/ ← agents 的工作目录
+└── outputs/ ← 最终交付物
+```
+
+### Context Engineering
+
+**隔离的 Sub-Agent Context**:每个 sub-agent 都在自己独立的上下文里运行。它看不到主 agent 的上下文,也看不到其他 sub-agents 的上下文。这样做的目的很直接,就是让它只聚焦当前任务,不被无关信息干扰。
+
+**摘要压缩**:在单个 session 内,DeerFlow 会比较积极地管理上下文,包括总结已完成的子任务、把中间结果转存到文件系统、压缩暂时不重要的信息。这样在长链路、多步骤任务里,它也能保持聚焦,而不会轻易把上下文窗口打爆。
+
+### 长期记忆
+
+大多数 agents 会在对话结束后把一切都忘掉,DeerFlow 不一样。
+
+跨 session 使用时,DeerFlow 会逐步积累关于你的持久 memory,包括你的个人偏好、知识背景,以及长期沉淀下来的工作习惯。你用得越多,它越了解你的写作风格、技术栈和重复出现的工作流。memory 保存在本地,控制权也始终在你手里。
+
+## 推荐模型
+
+DeerFlow 对模型没有强绑定,只要实现了 OpenAI 兼容 API 的 LLM,理论上都可以接入。不过在下面这些能力上表现更强的模型,通常会更适合 DeerFlow:
+
+- **长上下文窗口**(100k+ tokens),适合深度研究和多步骤任务
+- **推理能力**,适合自适应规划和复杂拆解
+- **多模态输入**,适合理解图片和视频
+- **稳定的 tool use 能力**,适合可靠的函数调用和结构化输出
+
+## 内嵌 Python Client
+
+DeerFlow 也可以作为内嵌的 Python 库使用,不必启动完整的 HTTP 服务。`DeerFlowClient` 提供了进程内的直接访问方式,覆盖所有 agent 和 Gateway 能力,返回的数据结构与 HTTP Gateway API 保持一致:
+
+```python
+from deerflow.client import DeerFlowClient
+
+client = DeerFlowClient()
+
+# Chat
+response = client.chat("Analyze this paper for me", thread_id="my-thread")
+
+# Streaming(LangGraph SSE 协议:values、messages-tuple、end)
+for event in client.stream("hello"):
+ if event.type == "messages-tuple" and event.data.get("type") == "ai":
+ print(event.data["content"])
+
+# 配置与管理:返回值与 Gateway 对齐的 dict
+models = client.list_models() # {"models": [...]}
+skills = client.list_skills() # {"skills": [...]}
+client.update_skill("web-search", enabled=True)
+client.upload_files("thread-1", ["./report.pdf"]) # {"success": True, "files": [...]}
+```
+
+所有返回 dict 的方法都会在 CI 中通过 Gateway 的 Pydantic 响应模型校验(`TestGatewayConformance`),以确保内嵌 client 始终和 HTTP API schema 保持同步。完整 API 说明见 `backend/packages/harness/deerflow/client.py`。
+
+## 文档
+
+- [贡献指南](CONTRIBUTING.md) - 开发环境搭建与协作流程
+- [配置指南](backend/docs/CONFIGURATION.md) - 安装与配置说明
+- [架构概览](backend/CLAUDE.md) - 技术架构说明
+- [后端架构](backend/README.md) - 后端架构与 API 参考
+
+## 参与贡献
+
+欢迎参与贡献。开发环境、工作流和相关规范见 [CONTRIBUTING.md](CONTRIBUTING.md)。
+
+目前回归测试已经覆盖 Docker sandbox 模式识别,以及 `backend/tests/` 中 provisioner kubeconfig-path 处理相关测试。
+
+## 许可证
+
+本项目采用 [MIT License](./LICENSE) 开源发布。
+
+## 致谢
+
+DeerFlow 建立在开源社区大量优秀工作的基础上。所有让 DeerFlow 成为可能的项目和贡献者,我们都心怀感谢。毫不夸张地说,我们是站在巨人的肩膀上继续往前走。
+
+特别感谢以下项目带来的关键支持:
+
+- **[LangChain](https://github.com/langchain-ai/langchain)**:它们提供的优秀框架支撑了我们的 LLM 交互与 chains,让整体集成和能力编排顺畅可用。
+- **[LangGraph](https://github.com/langchain-ai/langgraph)**:它们在多 agent 编排上的创新方式,是 DeerFlow 复杂工作流得以成立的重要基础。
+
+这些项目体现了开源协作真正的力量,我们也很高兴能继续建立在这些基础之上。
+
+### 核心贡献者
+
+感谢 `DeerFlow` 的核心作者,是他们的判断、投入和持续推进,才让这个项目真正落地:
+
+- **[Daniel Walnut](https://github.com/hetaoBackend/)**
+- **[Henry Li](https://github.com/magiccube/)**
+
+## Star History
+
+[](https://star-history.com/#bytedance/deer-flow&Date)