* refactor: extract shared skill installer and upload manager to harness Move duplicated business logic from Gateway routers and Client into shared harness modules, eliminating code duplication. New shared modules: - deerflow.skills.installer: 6 functions (zip security, extraction, install) - deerflow.uploads.manager: 7 functions (normalize, deduplicate, validate, list, delete, get_uploads_dir, ensure_uploads_dir) Key improvements: - SkillAlreadyExistsError replaces stringly-typed 409 status routing - normalize_filename rejects backslash-containing filenames - Read paths (list/delete) no longer mkdir via get_uploads_dir - Write paths use ensure_uploads_dir for explicit directory creation - list_files_in_dir does stat inside scandir context (no re-stat) - install_skill_from_archive uses single is_file() check (one syscall) - Fix agent config key not reset on update_mcp_config/update_skill Tests: 42 new (22 installer + 20 upload manager) + client hardening * refactor: centralize upload URL construction and clean up installer - Extract upload_virtual_path(), upload_artifact_url(), enrich_file_listing() into shared manager.py, eliminating 6 duplicated URL constructions across Gateway router and Client - Derive all upload URLs from VIRTUAL_PATH_PREFIX constant instead of hardcoded "mnt/user-data/uploads" strings - Eliminate TOCTOU pre-checks and double file read in installer — single ZipFile() open with exception handling replaces is_file() + is_zipfile() + ZipFile() sequence - Add missing re-exports: ensure_uploads_dir in uploads/__init__.py, SkillAlreadyExistsError in skills/__init__.py - Remove redundant .lower() on already-lowercase CONVERTIBLE_EXTENSIONS - Hoist sandbox_uploads_dir(thread_id) before loop in uploads router * fix: add input validation for thread_id and filename length - Reject thread_id containing unsafe filesystem characters (only allow alphanumeric, hyphens, underscores, dots) — prevents 500 on inputs like <script> or shell metacharacters - Reject filenames longer than 255 bytes (OS limit) in normalize_filename - Gateway upload router maps ValueError to 400 for invalid thread_id * fix: address PR review — symlink safety, input validation coverage, error ordering - list_files_in_dir: use follow_symlinks=False to prevent symlink metadata leakage; check is_dir() instead of exists() for non-directory paths - install_skill_from_archive: restore is_file() pre-check before extension validation so error messages match the documented exception contract - validate_thread_id: move from ensure_uploads_dir to get_uploads_dir so all entry points (upload/list/delete) are protected - delete_uploaded_file: catch ValueError from thread_id validation (was 500) - requires_llm marker: also skip when OPENAI_API_KEY is unset - e2e fixture: update TitleMiddleware exclusion comment (kept filtering — middleware triggers extra LLM calls that add non-determinism to tests) * chore: revert uv.lock to main — no dependency changes in this PR * fix: use monkeypatch for global config in e2e fixture to prevent test pollution The e2e_env fixture was calling set_title_config() and set_summarization_config() directly, which mutated global singletons without automatic cleanup. When pytest ran test_client_e2e.py before test_title_middleware_core_logic.py, the leaked enabled=False caused 5 title tests to fail in CI. Switched to monkeypatch.setattr on the module-level private variables so pytest restores the originals after each test. * fix: address code review — URL encoding, API consistency, test isolation - upload_artifact_url: percent-encode filename to handle spaces/#/? - deduplicate_filename: mutate seen set in place (caller no longer needs manual .add() — less error-prone API) - list_files_in_dir: document that size is int, enrich stringifies - e2e fixture: monkeypatch _app_config instead of set_app_config() to prevent global singleton pollution (same pattern as title/summarization fix) - _make_e2e_config: read LLM connection details from env vars so external contributors can override defaults - Update tests to match new deduplicate_filename contract * docs: rewrite RFC in English and add alternatives/breaking changes sections * fix: address code review feedback on PR #1202 - Rename deduplicate_filename to claim_unique_filename to make the in-place set mutation explicit in the function name - Replace PermissionError with PathTraversalError(ValueError) for path traversal detection — malformed input is 400, not 403 * fix: set _app_config_is_custom in e2e test fixture to prevent config.yaml lookup in CI --------- Co-authored-by: greatmengqi <chenmengqi.0376@bytedance.com> Co-authored-by: Willem Jiang <willem.jiang@gmail.com> Co-authored-by: DanielWalnut <45447813+hetaoBackend@users.noreply.github.com>
🦌 DeerFlow - 2.0
English | 中文 | 日本語 | Français | Русский
![]()
On February 28th, 2026, DeerFlow claimed the 🏆 #1 spot on GitHub Trending following the launch of version 2. Thanks a million to our incredible community — you made this happen! 💪🔥
DeerFlow (Deep Exploration and Efficient Research Flow) is an open-source super agent harness that orchestrates sub-agents, memory, and sandboxes to do almost anything — powered by extensible skills.
https://github.com/user-attachments/assets/a8bcadc4-e040-4cf2-8fda-dd768b999c18
Note
DeerFlow 2.0 is a ground-up rewrite. It shares no code with v1. If you're looking for the original Deep Research framework, it's maintained on the
1.xbranch — contributions there are still welcome. Active development has moved to 2.0.
Official Website
Learn more and see real demos on our official website.
Coding Plan from ByteDance Volcengine
- We strongly recommend using Doubao-Seed-2.0-Code, DeepSeek v3.2 and Kimi 2.5 to run DeerFlow
- Learn more
- 中国大陆地区的开发者请点击这里
InfoQuest
DeerFlow has newly integrated the intelligent search and crawling toolset independently developed by BytePlus--InfoQuest (supports free online experience)
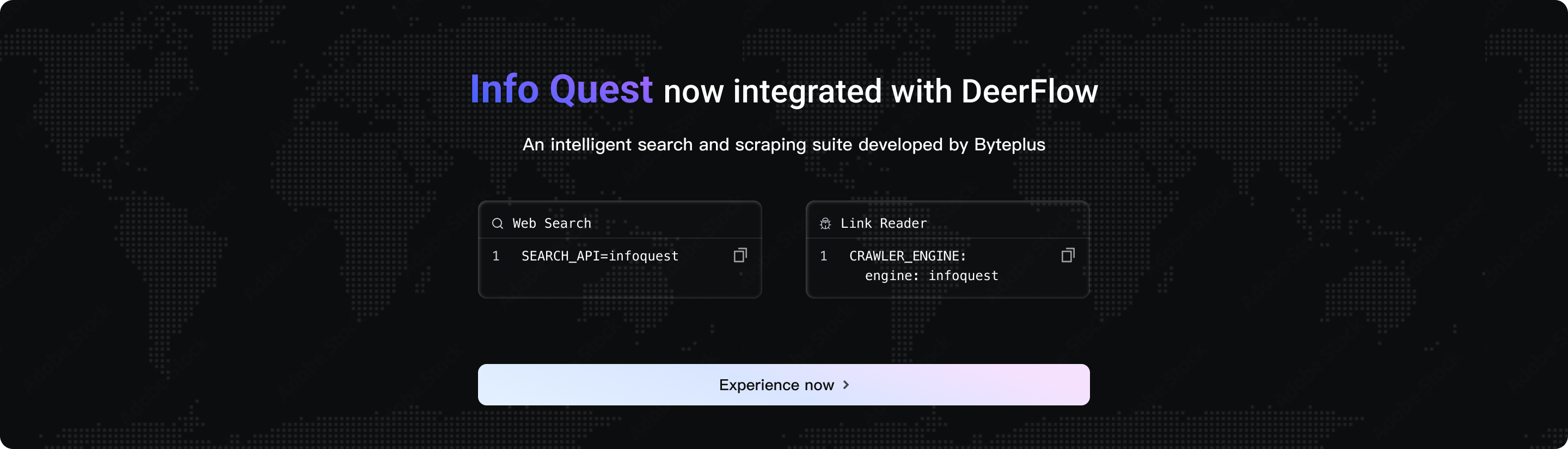
Table of Contents
- 🦌 DeerFlow - 2.0
Quick Start
Configuration
-
Clone the DeerFlow repository
git clone https://github.com/bytedance/deer-flow.git cd deer-flow -
Generate local configuration files
From the project root directory (
deer-flow/), run:make configThis command creates local configuration files based on the provided example templates.
-
Configure your preferred model(s)
Edit
config.yamland define at least one model:models: - name: gpt-4 # Internal identifier display_name: GPT-4 # Human-readable name use: langchain_openai:ChatOpenAI # LangChain class path model: gpt-4 # Model identifier for API api_key: $OPENAI_API_KEY # API key (recommended: use env var) max_tokens: 4096 # Maximum tokens per request temperature: 0.7 # Sampling temperature - name: openrouter-gemini-2.5-flash display_name: Gemini 2.5 Flash (OpenRouter) use: langchain_openai:ChatOpenAI model: google/gemini-2.5-flash-preview api_key: $OPENAI_API_KEY # OpenRouter still uses the OpenAI-compatible field name here base_url: https://openrouter.ai/api/v1 - name: gpt-5-responses display_name: GPT-5 (Responses API) use: langchain_openai:ChatOpenAI model: gpt-5 api_key: $OPENAI_API_KEY use_responses_api: true output_version: responses/v1OpenRouter and similar OpenAI-compatible gateways should be configured with
langchain_openai:ChatOpenAIplusbase_url. If you prefer a provider-specific environment variable name, pointapi_keyat that variable explicitly (for exampleapi_key: $OPENROUTER_API_KEY).To route OpenAI models through
/v1/responses, keep usinglangchain_openai:ChatOpenAIand setuse_responses_api: truewithoutput_version: responses/v1.CLI-backed provider examples:
models: - name: gpt-5.4 display_name: GPT-5.4 (Codex CLI) use: deerflow.models.openai_codex_provider:CodexChatModel model: gpt-5.4 supports_thinking: true supports_reasoning_effort: true - name: claude-sonnet-4.6 display_name: Claude Sonnet 4.6 (Claude Code OAuth) use: deerflow.models.claude_provider:ClaudeChatModel model: claude-sonnet-4-6 max_tokens: 4096 supports_thinking: true- Codex CLI reads
~/.codex/auth.json - The Codex Responses endpoint currently rejects
max_tokensandmax_output_tokens, soCodexChatModeldoes not expose a request-level token cap - Claude Code accepts
CLAUDE_CODE_OAUTH_TOKEN,ANTHROPIC_AUTH_TOKEN,CLAUDE_CODE_OAUTH_TOKEN_FILE_DESCRIPTOR,CLAUDE_CODE_CREDENTIALS_PATH, or plaintext~/.claude/.credentials.json - On macOS, DeerFlow does not probe Keychain automatically. Export Claude Code auth explicitly if needed:
eval "$(python3 scripts/export_claude_code_oauth.py --print-export)" - Codex CLI reads
-
Set API keys for your configured model(s)
Choose one of the following methods:
-
Option A: Edit the
.envfile in the project root (Recommended)TAVILY_API_KEY=your-tavily-api-key OPENAI_API_KEY=your-openai-api-key # OpenRouter also uses OPENAI_API_KEY when your config uses langchain_openai:ChatOpenAI + base_url. # Add other provider keys as needed INFOQUEST_API_KEY=your-infoquest-api-key -
Option B: Export environment variables in your shell
export OPENAI_API_KEY=your-openai-api-keyFor CLI-backed providers:
- Codex CLI:
~/.codex/auth.json - Claude Code OAuth: explicit env/file handoff or
~/.claude/.credentials.json
- Codex CLI:
-
Option C: Edit
config.yamldirectly (Not recommended for production)models: - name: gpt-4 api_key: your-actual-api-key-here # Replace placeholder
Running the Application
Option 1: Docker (Recommended)
Development (hot-reload, source mounts):
make docker-init # Pull sandbox image (only once or when image updates)
make docker-start # Start services (auto-detects sandbox mode from config.yaml)
make docker-start starts provisioner only when config.yaml uses provisioner mode (sandbox.use: deerflow.community.aio_sandbox:AioSandboxProvider with provisioner_url).
Backend processes automatically pick up config.yaml changes on the next config access, so model metadata updates do not require a manual restart during development.
Tip
On Linux, if Docker-based commands fail with
permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock, add your user to thedockergroup and re-login before retrying. See CONTRIBUTING.md for the full fix.
Production (builds images locally, mounts runtime config and data):
make up # Build images and start all production services
make down # Stop and remove containers
Note
The LangGraph agent server currently runs via
langgraph dev(the open-source CLI server).
Access: http://localhost:2026
See CONTRIBUTING.md for detailed Docker development guide.
Option 2: Local Development
If you prefer running services locally:
Prerequisite: complete the "Configuration" steps above first (make config and model API keys). make dev requires a valid configuration file (defaults to config.yaml in the project root; can be overridden via DEER_FLOW_CONFIG_PATH).
-
Check prerequisites:
make check # Verifies Node.js 22+, pnpm, uv, nginx -
Install dependencies:
make install # Install backend + frontend dependencies -
(Optional) Pre-pull sandbox image:
# Recommended if using Docker/Container-based sandbox make setup-sandbox -
Start services:
make dev -
Access: http://localhost:2026
Advanced
Sandbox Mode
DeerFlow supports multiple sandbox execution modes:
- Local Execution (runs sandbox code directly on the host machine)
- Docker Execution (runs sandbox code in isolated Docker containers)
- Docker Execution with Kubernetes (runs sandbox code in Kubernetes pods via provisioner service)
For Docker development, service startup follows config.yaml sandbox mode. In Local/Docker modes, provisioner is not started.
See the Sandbox Configuration Guide to configure your preferred mode.
MCP Server
DeerFlow supports configurable MCP servers and skills to extend its capabilities.
For HTTP/SSE MCP servers, OAuth token flows are supported (client_credentials, refresh_token).
See the MCP Server Guide for detailed instructions.
IM Channels
DeerFlow supports receiving tasks from messaging apps. Channels auto-start when configured — no public IP required for any of them.
| Channel | Transport | Difficulty |
|---|---|---|
| Telegram | Bot API (long-polling) | Easy |
| Slack | Socket Mode | Moderate |
| Feishu / Lark | WebSocket | Moderate |
Configuration in config.yaml:
channels:
# LangGraph Server URL (default: http://localhost:2024)
langgraph_url: http://localhost:2024
# Gateway API URL (default: http://localhost:8001)
gateway_url: http://localhost:8001
# Optional: global session defaults for all mobile channels
session:
assistant_id: lead_agent
config:
recursion_limit: 100
context:
thinking_enabled: true
is_plan_mode: false
subagent_enabled: false
feishu:
enabled: true
app_id: $FEISHU_APP_ID
app_secret: $FEISHU_APP_SECRET
slack:
enabled: true
bot_token: $SLACK_BOT_TOKEN # xoxb-...
app_token: $SLACK_APP_TOKEN # xapp-... (Socket Mode)
allowed_users: [] # empty = allow all
telegram:
enabled: true
bot_token: $TELEGRAM_BOT_TOKEN
allowed_users: [] # empty = allow all
# Optional: per-channel / per-user session settings
session:
assistant_id: mobile_agent
context:
thinking_enabled: false
users:
"123456789":
assistant_id: vip_agent
config:
recursion_limit: 150
context:
thinking_enabled: true
subagent_enabled: true
Set the corresponding API keys in your .env file:
# Telegram
TELEGRAM_BOT_TOKEN=123456789:ABCdefGHIjklMNOpqrSTUvwxYZ
# Slack
SLACK_BOT_TOKEN=xoxb-...
SLACK_APP_TOKEN=xapp-...
# Feishu / Lark
FEISHU_APP_ID=cli_xxxx
FEISHU_APP_SECRET=your_app_secret
Telegram Setup
- Chat with @BotFather, send
/newbot, and copy the HTTP API token. - Set
TELEGRAM_BOT_TOKENin.envand enable the channel inconfig.yaml.
Slack Setup
- Create a Slack App at api.slack.com/apps → Create New App → From scratch.
- Under OAuth & Permissions, add Bot Token Scopes:
app_mentions:read,chat:write,im:history,im:read,im:write,files:write. - Enable Socket Mode → generate an App-Level Token (
xapp-…) withconnections:writescope. - Under Event Subscriptions, subscribe to bot events:
app_mention,message.im. - Set
SLACK_BOT_TOKENandSLACK_APP_TOKENin.envand enable the channel inconfig.yaml.
Feishu / Lark Setup
- Create an app on Feishu Open Platform → enable Bot capability.
- Add permissions:
im:message,im:message.p2p_msg:readonly,im:resource. - Under Events, subscribe to
im.message.receive_v1and select Long Connection mode. - Copy the App ID and App Secret. Set
FEISHU_APP_IDandFEISHU_APP_SECRETin.envand enable the channel inconfig.yaml.
Commands
Once a channel is connected, you can interact with DeerFlow directly from the chat:
| Command | Description |
|---|---|
/new |
Start a new conversation |
/status |
Show current thread info |
/models |
List available models |
/memory |
View memory |
/help |
Show help |
Messages without a command prefix are treated as regular chat — DeerFlow creates a thread and responds conversationally.
From Deep Research to Super Agent Harness
DeerFlow started as a Deep Research framework — and the community ran with it. Since launch, developers have pushed it far beyond research: building data pipelines, generating slide decks, spinning up dashboards, automating content workflows. Things we never anticipated.
That told us something important: DeerFlow wasn't just a research tool. It was a harness — a runtime that gives agents the infrastructure to actually get work done.
So we rebuilt it from scratch.
DeerFlow 2.0 is no longer a framework you wire together. It's a super agent harness — batteries included, fully extensible. Built on LangGraph and LangChain, it ships with everything an agent needs out of the box: a filesystem, memory, skills, sandboxed execution, and the ability to plan and spawn sub-agents for complex, multi-step tasks.
Use it as-is. Or tear it apart and make it yours.
Core Features
Skills & Tools
Skills are what make DeerFlow do almost anything.
A standard Agent Skill is a structured capability module — a Markdown file that defines a workflow, best practices, and references to supporting resources. DeerFlow ships with built-in skills for research, report generation, slide creation, web pages, image and video generation, and more. But the real power is extensibility: add your own skills, replace the built-in ones, or combine them into compound workflows.
Skills are loaded progressively — only when the task needs them, not all at once. This keeps the context window lean and makes DeerFlow work well even with token-sensitive models.
When you install .skill archives through the Gateway, DeerFlow accepts standard optional frontmatter metadata such as version, author, and compatibility instead of rejecting otherwise valid external skills.
Tools follow the same philosophy. DeerFlow comes with a core toolset — web search, web fetch, file operations, bash execution — and supports custom tools via MCP servers and Python functions. Swap anything. Add anything.
Gateway-generated follow-up suggestions now normalize both plain-string model output and block/list-style rich content before parsing the JSON array response, so provider-specific content wrappers do not silently drop suggestions.
# Paths inside the sandbox container
/mnt/skills/public
├── research/SKILL.md
├── report-generation/SKILL.md
├── slide-creation/SKILL.md
├── web-page/SKILL.md
└── image-generation/SKILL.md
/mnt/skills/custom
└── your-custom-skill/SKILL.md ← yours
Claude Code Integration
The claude-to-deerflow skill lets you interact with a running DeerFlow instance directly from Claude Code. Send research tasks, check status, manage threads — all without leaving the terminal.
Install the skill:
npx skills add https://github.com/bytedance/deer-flow --skill claude-to-deerflow
Then make sure DeerFlow is running (default at http://localhost:2026) and use the /claude-to-deerflow command in Claude Code.
What you can do:
- Send messages to DeerFlow and get streaming responses
- Choose execution modes: flash (fast), standard, pro (planning), ultra (sub-agents)
- Check DeerFlow health, list models/skills/agents
- Manage threads and conversation history
- Upload files for analysis
Environment variables (optional, for custom endpoints):
DEERFLOW_URL=http://localhost:2026 # Unified proxy base URL
DEERFLOW_GATEWAY_URL=http://localhost:2026 # Gateway API
DEERFLOW_LANGGRAPH_URL=http://localhost:2026/api/langgraph # LangGraph API
See skills/public/claude-to-deerflow/SKILL.md for the full API reference.
Sub-Agents
Complex tasks rarely fit in a single pass. DeerFlow decomposes them.
The lead agent can spawn sub-agents on the fly — each with its own scoped context, tools, and termination conditions. Sub-agents run in parallel when possible, report back structured results, and the lead agent synthesizes everything into a coherent output.
This is how DeerFlow handles tasks that take minutes to hours: a research task might fan out into a dozen sub-agents, each exploring a different angle, then converge into a single report — or a website — or a slide deck with generated visuals. One harness, many hands.
Sandbox & File System
DeerFlow doesn't just talk about doing things. It has its own computer.
Each task runs inside an isolated Docker container with a full filesystem — skills, workspace, uploads, outputs. The agent reads, writes, and edits files. It executes bash commands and codes. It views images. All sandboxed, all auditable, zero contamination between sessions.
This is the difference between a chatbot with tool access and an agent with an actual execution environment.
# Paths inside the sandbox container
/mnt/user-data/
├── uploads/ ← your files
├── workspace/ ← agents' working directory
└── outputs/ ← final deliverables
Context Engineering
Isolated Sub-Agent Context: Each sub-agent runs in its own isolated context. This means that the sub-agent will not be able to see the context of the main agent or other sub-agents. This is important to ensure that the sub-agent is able to focus on the task at hand and not be distracted by the context of the main agent or other sub-agents.
Summarization: Within a session, DeerFlow manages context aggressively — summarizing completed sub-tasks, offloading intermediate results to the filesystem, compressing what's no longer immediately relevant. This lets it stay sharp across long, multi-step tasks without blowing the context window.
Long-Term Memory
Most agents forget everything the moment a conversation ends. DeerFlow remembers.
Across sessions, DeerFlow builds a persistent memory of your profile, preferences, and accumulated knowledge. The more you use it, the better it knows you — your writing style, your technical stack, your recurring workflows. Memory is stored locally and stays under your control.
Memory updates now skip duplicate fact entries at apply time, so repeated preferences and context do not accumulate endlessly across sessions.
Recommended Models
DeerFlow is model-agnostic — it works with any LLM that implements the OpenAI-compatible API. That said, it performs best with models that support:
- Long context windows (100k+ tokens) for deep research and multi-step tasks
- Reasoning capabilities for adaptive planning and complex decomposition
- Multimodal inputs for image understanding and video comprehension
- Strong tool-use for reliable function calling and structured outputs
Embedded Python Client
DeerFlow can be used as an embedded Python library without running the full HTTP services. The DeerFlowClient provides direct in-process access to all agent and Gateway capabilities, returning the same response schemas as the HTTP Gateway API. The HTTP Gateway also exposes DELETE /api/threads/{thread_id} to remove DeerFlow-managed local thread data after the LangGraph thread itself has been deleted:
from deerflow.client import DeerFlowClient
client = DeerFlowClient()
# Chat
response = client.chat("Analyze this paper for me", thread_id="my-thread")
# Streaming (LangGraph SSE protocol: values, messages-tuple, end)
for event in client.stream("hello"):
if event.type == "messages-tuple" and event.data.get("type") == "ai":
print(event.data["content"])
# Configuration & management — returns Gateway-aligned dicts
models = client.list_models() # {"models": [...]}
skills = client.list_skills() # {"skills": [...]}
client.update_skill("web-search", enabled=True)
client.upload_files("thread-1", ["./report.pdf"]) # {"success": True, "files": [...]}
All dict-returning methods are validated against Gateway Pydantic response models in CI (TestGatewayConformance), ensuring the embedded client stays in sync with the HTTP API schemas. See backend/packages/harness/deerflow/client.py for full API documentation.
Documentation
- Contributing Guide - Development environment setup and workflow
- Configuration Guide - Setup and configuration instructions
- Architecture Overview - Technical architecture details
- Backend Architecture - Backend architecture and API reference
Contributing
We welcome contributions! Please see CONTRIBUTING.md for development setup, workflow, and guidelines.
Regression coverage includes Docker sandbox mode detection and provisioner kubeconfig-path handling tests in backend/tests/.
License
This project is open source and available under the MIT License.
Acknowledgments
DeerFlow is built upon the incredible work of the open-source community. We are deeply grateful to all the projects and contributors whose efforts have made DeerFlow possible. Truly, we stand on the shoulders of giants.
We would like to extend our sincere appreciation to the following projects for their invaluable contributions:
- LangChain: Their exceptional framework powers our LLM interactions and chains, enabling seamless integration and functionality.
- LangGraph: Their innovative approach to multi-agent orchestration has been instrumental in enabling DeerFlow's sophisticated workflows.
These projects exemplify the transformative power of open-source collaboration, and we are proud to build upon their foundations.
Key Contributors
A heartfelt thank you goes out to the core authors of DeerFlow, whose vision, passion, and dedication have brought this project to life:
Your unwavering commitment and expertise have been the driving force behind DeerFlow's success. We are honored to have you at the helm of this journey.